
AI เอเจนต์ (Agentic AI) กำลังเปลี่ยนวิธีการทำงานของผู้ใช้ให้มีประสิทธิภาพยิ่งขึ้น หลังจากความสำเร็จของ OpenClaw ชุมชนเทคโนโลยีต่างให้การตอบรับเฟรมเวิร์กเอเจนต์แบบโอเพนซอร์สรุ่นใหม่ๆ อย่างท่วมท้น ล่าสุดคือ Hermes Agent ซึ่งมียอดสตาร์บน GitHub ทะลุ 140,000 ดวงภายในเวลาไม่ถึงสามเดือน และข้อมูลจาก OpenRouter ระบุว่า ในสัปดาห์ที่ผ่านมา Hermes ได้กลายเป็นเอเจนต์ AI ที่มีการใช้งานมากที่สุดในโลก
ความสามารถเด่นของเอเจนต์ AI ในเครื่อง Hermes
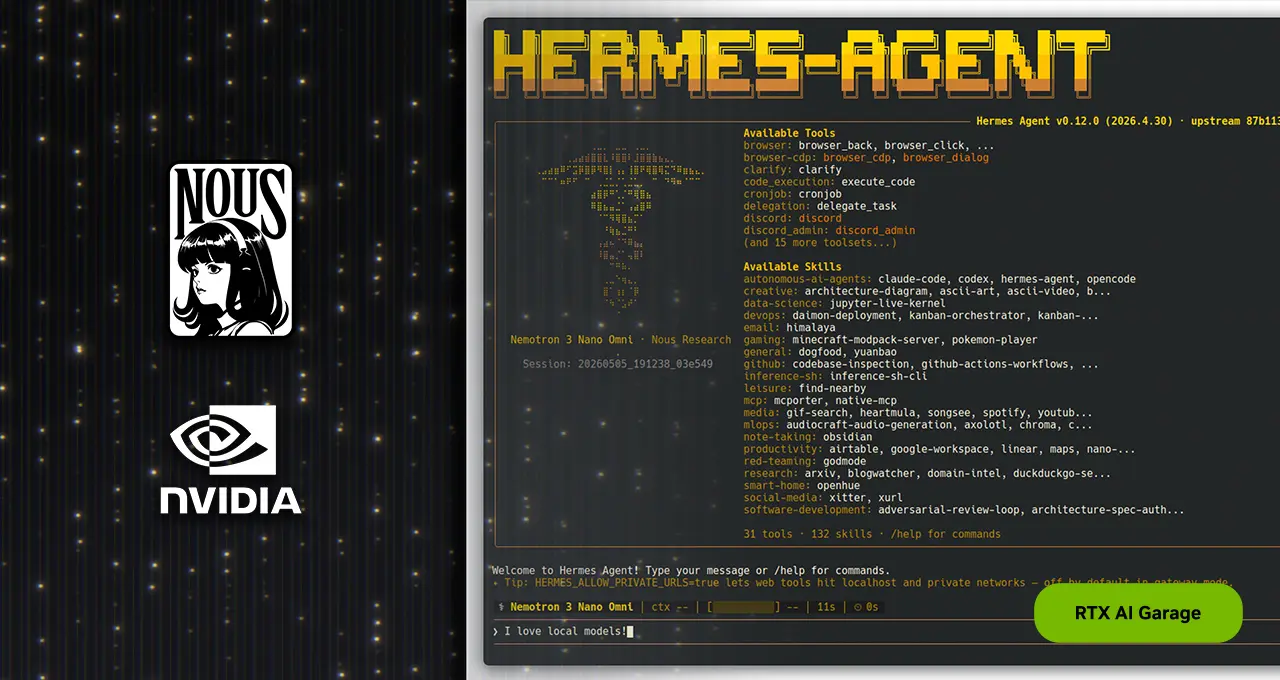
เช่นเดียวกับเอเจนต์ยอดนิยมทั่วไป Hermes สามารถเชื่อมต่อกับแอปพลิเคชันส่งข้อความ เข้าถึงไฟล์และแอปพลิเคชันในเครื่อง และทำงานได้ตลอด 24 ชั่วโมง แต่มี 4 ความสามารถหลักที่ทำให้ Hermes โดดเด่นกว่าใคร:
- ทักษะที่วิวัฒนาการได้เอง (Self-Evolving Skills): Hermes สามารถเขียนและปรับปรุงทักษะของตัวเองได้ ทุกครั้งที่พบกับงานที่ซับซ้อนหรือได้รับคำติชม (Feedback) ระบบจะบันทึกสิ่งที่เรียนรู้ไว้เป็นทักษะ เพื่อให้สามารถปรับตัวและเก่งขึ้นตามกาลเวลา
- การใช้เอเจนต์ย่อยแบบแยกส่วน (Contained Sub-Agents): Hermes จะสร้างเอเจนต์ย่อยเปรียบเสมือน “พนักงานชั่วคราว” เพื่อจัดการงานย่อยโดยเฉพาะ โดยกำหนดบริบทและชุดเครื่องมือให้โฟกัสเฉพาะเรื่อง วิธีนี้ช่วยให้การจัดการงานเป็นระเบียบ ลดความสับสน และทำให้ Hermes ทำงานได้แม้จะมีหน้าต่างบริบท (Context Windows) ขนาดเล็ก ซึ่งเหมาะสำหรับโมเดลที่รันในเครื่อง
- ความน่าเชื่อถือตั้งแต่การออกแบบ (Reliability by Design): Nous Research ได้คัดสรรและทดสอบความทนทาน (Stress-tests) ของทุกทักษะ เครื่องมือ และปลั๊กอิน ส่งผลให้ Hermes สามารถใช้งานได้ทันทีแม้จะใช้กับโมเดลในเครื่องขนาด 30 พันล้านพารามิเตอร์ โดยไม่ต้องคอยแก้ไขบั๊ก (Debugging) ตลอดเวลาเหมือนเฟรมเวิร์กส่วนใหญ่
- โมเดลเดิม แต่ผลลัพธ์ดีกว่า (Same model, better results): จากการเปรียบเทียบโดยนักพัฒนาที่ใช้โมเดลเดียวกันในเฟรมเวิร์กที่ต่างกัน พบว่า Hermes ให้ผลลัพธ์ที่เหนือกว่าอย่างสม่ำเสมอ เนื่องจาก Hermes ทำหน้าที่เป็นชั้นจัดการระบบ (Orchestration Layer) ที่ทำงานเชิงรุก ไม่ใช่เพียงแค่เปลือกหุ้ม (Thin Wrapper) ทำให้สามารถสร้างเอเจนต์บนอุปกรณ์ที่ทำงานต่อเนื่องได้ แทนที่จะประมวลผลเป็นรายครั้ง
เนื่องจากทั้ง Hermes และ LLM ถูกออกแบบมาเพื่อประมวลผลภายในเครื่อง (ไม่ผ่านคลาวด์) คุณภาพของฮาร์ดแวร์จึงส่งผลโดยตรงต่อประสบการณ์ของผู้ใช้ ซึ่ง GPU NVIDIA RTX ถูกสร้างมาเพื่อรองรับเวิร์กโหลดประเภทนี้โดยเฉพาะ
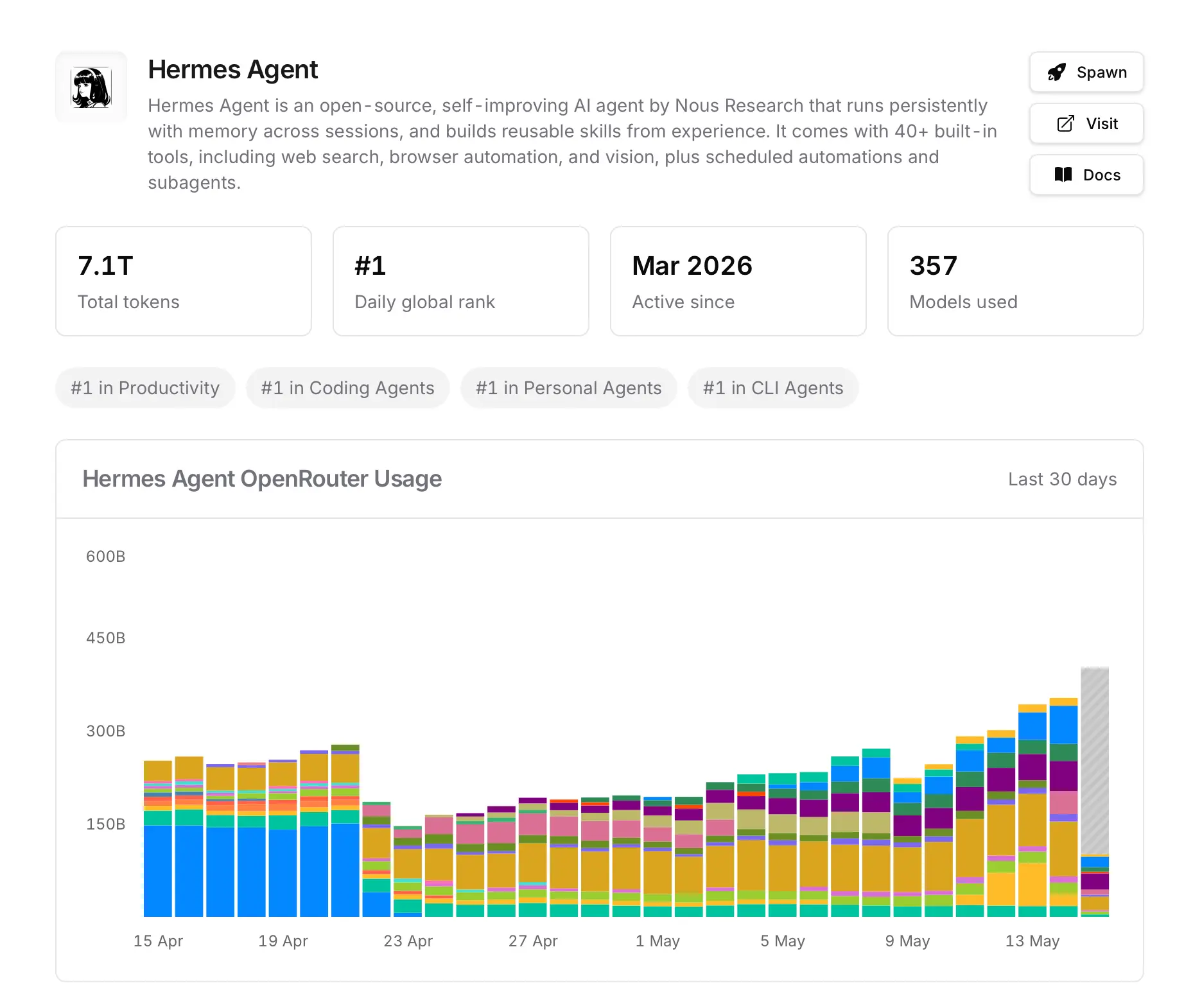
Qwen 3.6: พลังประมวลผลระดับ Data Center ในเครื่องคุณ
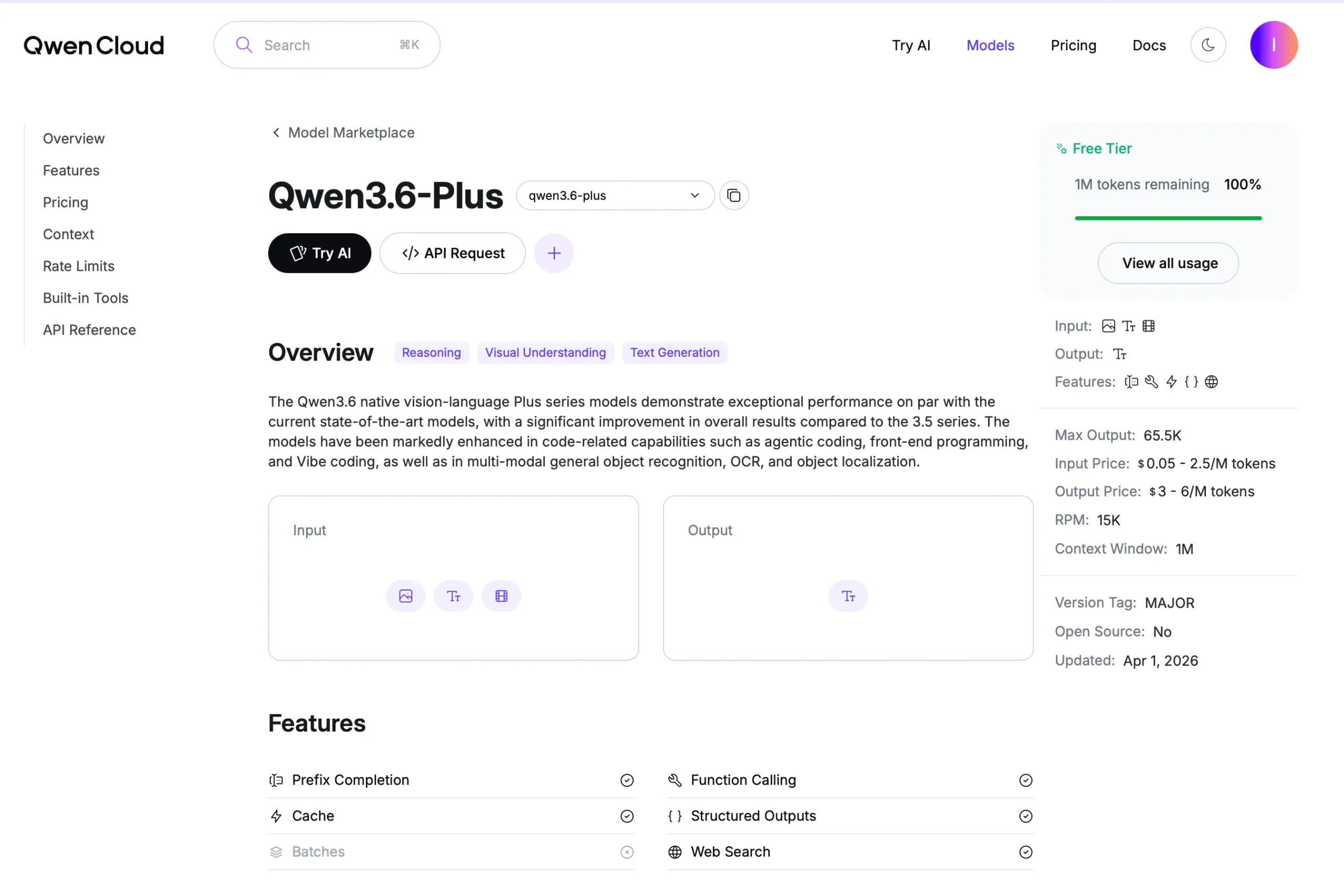
โมเดล Qwen 3.6 ต่อยอดมาจากซีรีส์ Qwen 3.5 ที่ได้รับคำชมอย่างมาก เพื่อยกระดับเอเจนต์ AI ในเครื่องให้ก้าวไปอีกขั้น โดยโมเดล Qwen 3.6 35B ใช้หน่วยความจำเพียงประมาณ 20GB แต่ให้ประสิทธิภาพเหนือกว่าโมเดลขนาด 120 พันล้านพารามิเตอร์ที่ต้องใช้หน่วยความจำถึง 70GB ขึ้นไป
นอกจากนี้ Qwen 3.6 27B ยังเป็นโมเดลแบบ Dense Model รุ่นใหม่ที่มีพารามิเตอร์ทำงานเชิงรุกมากขึ้น ทำให้มีความแม่นยำเทียบเท่ากับโมเดลขนาด 400 พันล้านพารามิเตอร์อย่าง Qwen 3.5 397B ทั้งที่มีขนาดเล็กกว่าถึง 16 เท่า การรันบน GPU RTX ระดับไฮเอนด์จึงมอบพลังคำนวณที่เพียงพอให้การทำงานรวดเร็วและลื่นไหล
เมื่อนำโมเดลเหล่านี้มาใช้กับ Hermes และรันบน GPU NVIDIA หรือ DGX Spark จะช่วยให้ทำงานได้เร็วที่สุด โดยมี NVIDIA Tensor Cores ช่วยเร่งการประมวลผล (AI Inference) เพื่อเพิ่มปริมาณงานที่ทำได้ (Throughput) และลดความหน่วง (Latency) ทำให้ Hermes สามารถทำงานหลายขั้นตอนหรือปรับปรุงทักษะตัวเองได้ภายในไม่กี่วินาที แทนที่จะต้องรอนานเป็นนาที
DGX Spark: คอมพิวเตอร์สำหรับเอเจนต์ที่พร้อมทำงานตลอดเวลา

เอเจนต์อย่าง Hermes ถูกออกแบบมาให้ทำงานต่อเนื่อง ทั้งการตอบสนองคำขอ วางแผนงานที่ซับซ้อน ดำเนินการอัตโนมัติ และพัฒนาตัวเอง NVIDIA DGX Spark จึงเป็นคู่หูที่สมบูรณ์แบบ ด้วยตัวเครื่องขนาดกะทัดรัดแต่ทรงพลัง ถูกสร้างมาเพื่อรองรับเวิร์กโฟลว์ของเอเจนต์ที่ต้องทำงานตลอดทั้งวัน
ด้วยหน่วยความจำแบบรวม (Unified Memory) 128GB และประสิทธิภาพ AI ระดับ 1 Petaflop ทำให้ NVIDIA DGX Spark สามารถรันโมเดลแบบ Mixture-of-Experts (MoE) ขนาด 120 พันล้านพารามิเตอร์ได้ตลอดวัน และเมื่อใช้กับ Qwen 3.6 35B ยิ่งช่วยให้ระบบทำงานได้ฉลาดขึ้นในขณะที่ใช้ทรัพยากรน้อยลง (Leaner footprint) ส่งผลให้รันได้เร็วขึ้นและรองรับการทำงานหลายอย่างพร้อมกัน (Concurrent Workloads) ได้ดีขึ้น
เริ่มต้นใช้งาน Hermes บนฮาร์ดแวร์ NVIDIA
การติดตั้ง Hermes แบบโลคัลบนฮาร์ดแวร์ NVIDIA นั้นง่ายมาก เพียงเข้าไปที่ Repository ของ Hermes บน GitHub และเลือกใช้กับโมเดลในเครื่องและ Runtime ที่คุณต้องการ โดยสามารถรัน Hermes คู่กับ Qwen 3.6 ผ่าน llama.cpp, LM Studio หรือ Ollama ซึ่ง Hermes รองรับ LM Studio และ Ollama มาให้ตั้งแต่ต้น (Out of the box) เพื่อให้ผู้ใช้เข้าถึงเอเจนต์ในเครื่องได้ง่ายที่สุด
ไม่ว่าจะเป็นผู้ที่ชื่นชอบ AI ในเครื่องที่ต้องการสำรวจขอบเขตของเอเจนต์ส่วนตัว หรือนักพัฒนาที่กำลังสร้างเครื่องมือเพื่อเพิ่มประสิทธิภาพการทำงาน Hermes บนฮาร์ดแวร์ NVIDIA มอบรากฐานที่ทรงพลังและน่าเชื่อถืออย่างยิ่ง
ICYMI: อัปเดตล่าสุดจาก RTX AI Garage
- NVIDIA RTX PRO GPUs ช่วยให้การสร้างโทเคน (Token Generation) เร็วขึ้นสูงสุด 3 เท่า เมื่อรันโมเดล Qwen 3.6 ด้วย llama.cpp ทำให้การตอบสนองเป็นแบบเรียลไทม์ ซึ่งจำเป็นมากสำหรับเอเจนต์ AI ในการจัดการงานหลายขั้นตอนและพัฒนาทักษะเพื่อให้เวิร์กโฟลว์ลื่นไหล
- โมเดล Google Gemma 4 ขนาด 26B และ 31B พร้อมใช้งานในรูปแบบ NVFP4 Checkpoints เพื่อประสิทธิภาพที่รวดเร็วยิ่งขึ้นบน GPU NVIDIA Blackwell เมื่อใช้คู่กับ Google Multi-Token Prediction Drafters จะช่วยเพิ่มความเร็วในการประมวลผล (Inference) ได้สูงสุด 3 เท่า โดยที่คุณภาพผลลัพธ์ยังคงเดิม ทำให้การใช้เหตุผลระดับสูง (Frontier-Class Reasoning) สามารถรันบน GPU NVIDIA ในเครื่องได้
- Mistral Medium เวอร์ชัน 3.5 ที่เปิดตัวเมื่อเดือนเมษายน ได้รับการอัปเดตให้รองรับ llama.cpp และ Ollama ทำให้สามารถรันบนระบบ NVIDIA RTX PRO และ DGX Spark ได้แล้ว
- NVIDIA เปิดตัว NVIDIA NemoClaw สแต็กโอเพนซอร์สที่ปรับปรุงประสบการณ์ OpenClaw บนอุปกรณ์ NVIDIA โดยเพิ่มความปลอดภัยและรองรับโมเดลในเครื่อง ปัจจุบัน NemoClaw รองรับ Windows Subsystem for Linux (WSL2) ทำให้นักพัฒนาและผู้ใช้งานบน Windows สามารถใช้งานได้สะดวกขึ้น
บทสรุป ทำไม AI ในเครื่องถึงสำคัญ?
การมาของ Hermes Agent และโมเดลประสิทธิภาพสูงอย่าง Qwen 3.6 สะท้อนให้เห็นถึงเทรนด์สำคัญในวงการ AI ปี 2026 — การย้ายจาก Cloud AI สู่ Local AI ซึ่งไม่ใช่แค่เรื่องความเป็นส่วนตัวหรือการประหยัดค่า API แต่เป็นความสามารถในการสร้างเอเจนต์ที่ทำงานได้ต่อเนื่องตลอด 24 ชั่วโมง โดยไม่ถูกจำกัดด้วย Latency หรือ Rate Limit ของบริการคลาวด์
เมื่อรวมกับฮาร์ดแวร์ระดับผู้บริโภคอย่าง NVIDIA RTX GPU และ DGX Spark ที่ทำให้การรันโมเดล 35B พารามิเตอร์เป็นเรื่องปกติ เราอาจกำลังเห็นจุดเปลี่ยนที่ AI ในเครื่อง จะกลายเป็นมาตรฐานใหม่สำหรับทั้งผู้ใช้ทั่วไปและนักพัฒนา ที่ต้องการควบคุมข้อมูลและเวิร์กโฟลว์ของตัวเองอย่างแท้จริง
คำถามคือ — เมื่อเอเจนต์ AI ที่พัฒนาตัวเองได้ รันอยู่ในเครื่องของคุณตลอด 24 ชั่วโมง โดยไม่ต้องพึ่งคลาวด์… คุณจะใช้มันทำอะไรเป็นอันดับแรก?
แหล่งที่มา: NVIDIA Blog