
Google เปิดตัว Gemma 4 12B โมเดล AI แบบ Multimodal รุ่นใหม่ที่มาพร้อมสถาปัตยกรรมแบบไม่ใช้ตัวเข้ารหัสแยก (Encoder-Free) สามารถรับข้อมูลภาพ และเสียงเข้าสู่โมเดลภาษาได้โดยตรง โดยใช้หน่วยความจำเพียง 16GB ทำให้สามารถรันบนแล็ปท็อปทั่วไปได้
Google เปิดตัว Gemma 4 12B โมเดล AI แบบไร้ Encoder รันบนแล็ปท็อปได้ 

Google ประกาศเปิดตัว Gemma 4 12B ซึ่งเป็นโมเดลปัญญาประดิษฐ์รุ่นล่าสุดของตระกูล Gemma ที่ออกแบบมาเพื่อนำความสามารถด้าน Agentic Multimodal Intelligence มาสู่แล็ปท็อปโดยตรง โดย Gemma 4 12B เป็นโมเดลระดับกลางที่เชื่อมช่องว่างระหว่าง Gemma E4B สำหรับอุปกรณ์พกพา และ Gemma 26B Mixture of Experts (MoE) สำหรับงานขั้นสูง โดยบรรจุประสิทธิภาพอันทรงพลังไว้ในหน่วยความจำที่ลดลงอย่างมาก นอกจากนี้ยังเป็นโมเดลขนาดกลางรุ่นแรกของ Google ที่รองรับการป้อนข้อมูลเสียงโดยตรง (Native Audio Input)
Google ยังเผยว่าโมเดลในตระกูล Gemma 4 มียอดดาวน์โหลดทะลุ 150 ล้านครั้งแล้ว โดยนักพัฒนาได้นำไปสร้างแอปพลิเคชันที่หลากหลาย ตั้งแต่แขนหุ่นยนต์สวมใส่ (Wearable Robotic Arms) สำหรับช่วยเหลือทางกายภาพ ไปจนถึงระบบรักษาความปลอดภัย AI ระดับองค์กร (Enterprise-Grade AI Security)
5 จุดเด่นของ Gemma 4 12B ที่แตกต่างจากโมเดลรุ่นอื่น
คุณสมบัติเด่นของ Gemma 4 12B ได้แก่:
- สถาปัตยกรรมรวมศูนย์แบบใหม่ (Novel Unified Architecture) — ไม่ใช้ตัวเข้ารหัสแยกสำหรับภาพ และเสียง แต่ส่งข้อมูลเข้าสู่ LLM Backbone โดยตรง
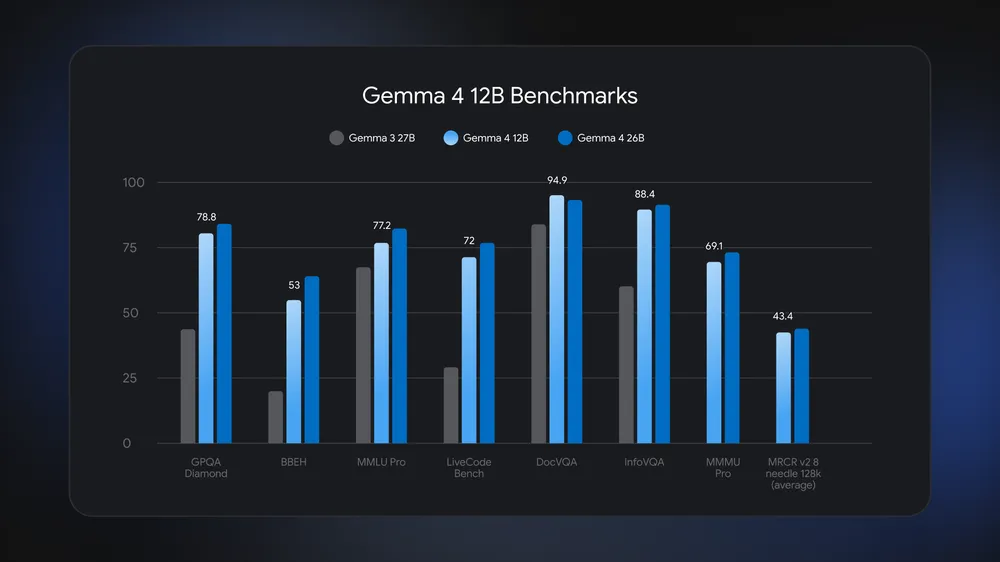
- การประมวลผลขั้นสูง (Advanced Reasoning) — มีประสิทธิภาพในเกณฑ์มาตรฐานใกล้เคียงกับโมเดล 26B MoE รองรับการให้เหตุผลแบบหลายขั้นตอน (Multi-Step Reasoning) และการทำงานแบบ Agentic Workflows
- รันบนแล็ปท็อปได้ — ต้องการ VRAM หรือ Unified Memory เพียง 16GB
- เปิดกว้าง และเข้าถึงได้ — ปล่อยภายใต้สัญญาอนุญาต Apache 2.0 รองรับเครื่องมือสำหรับนักพัฒนาหลากหลาย
- พร้อมระบบเร่งความเร็ว — มาพร้อม Multi-Token Prediction (MTP) Drafters เพื่อลดความหน่วงในการประมวลผล
สถาปัตยกรรมแบบไร้ตัวเข้ารหัสแยกทำงานอย่างไร
จุดเด่นสำคัญของ Gemma 4 12B คือการประมวลผลภาพ และเสียงที่ได้รับการออกแบบให้มีประสิทธิภาพสูง โมเดล Multimodal แบบดั้งเดิมมักใช้ตัวเข้ารหัส (Encoder) แยกต่างหากในการแปลงภาพ และเสียงก่อนส่งให้โมเดลภาษา ซึ่งทำให้เกิดความหน่วง (Latency) และใช้หน่วยความจำมากขึ้น Google จึงออกแบบ Gemma 4 12B ให้มีสถาปัตยกรรมแบบไม่ใช้ตัวเข้ารหัส (Encoder-Free Architecture) โดยผสานการป้อนข้อมูลภาพ และเสียงเข้ากับ LLM Backbone โดยตรง
สำหรับการประมวลผลภาพ (Vision) ทางทีมพัฒนาได้แทนที่ตัวเข้ารหัสภาพของ Gemma 4 เดิมด้วยโมดูลฝังข้อมูลแบบเบา (Lightweight Embedding Module) ที่ประกอบด้วยการคูณเมทริกซ์เพียงครั้งเดียวร่วมกับการฝังตำแหน่ง (Positional Embedding) และการทำ Normalization โดยปล่อยให้ LLM Backbone จัดการการประมวลผลภาพโดยตรง
ส่วนการประมวลผลเสียง (Audio) นั้นถูกทำให้ง่ายขึ้นไปอีกขั้น โดยทีมพัฒนาถอดตัวเข้ารหัสเสียงออกทั้งหมด และฉายสัญญาณเสียงดิบ (Raw Audio Signal) เข้าสู่พื้นที่มิติเดียวกับโทเค็นข้อความโดยตรง
วิธีเริ่มต้นใช้งาน Gemma 4 12B
นักพัฒนาสามารถเริ่มต้นใช้งาน Gemma 4 12B ได้หลากหลายช่องทาง ได้แก่:
• ทดลองใช้งานผ่าน LM Studio, Ollama, Google AI Edge Gallery App, แอป Google AI Edge Eloquent และ LiteRT-LM CLI
• ดาวน์โหลด Pretrained และ Instruction-Tuned Checkpoints จาก Hugging Face และ Kaggle
• ศึกษาเอกสารสำหรับนักพัฒนา และ Quick Start Notebook
• ใช้งานเครื่องมือพัฒนายอดนิยม เช่น Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM หรือ ปรับแต่งโมเดลด้วย Unsloth
• ใช้ Gemma Skills Repository อย่างเป็นทางการในการพัฒนา Agentic Applications
• เปิดให้บริการบน Google Cloud ผ่าน Gemini Enterprise Agent Platform Model Garden, Cloud Run และ GKE
ที่มา: blog.google