
นักวิจัย Apple ร่วมพัฒนา AI กับมหาวิทยาลัย Renmin ของจีน ชื่อโมเดล VSSFlow AI สร้างเสียง และคำพูดจากวิดีโอเงียบได้ในระบบเดียว พร้อมเปิด Open-source ให้ใช้ฟรี
Apple ร่วมพัฒนา AI สร้างเสียง และคำพูดจากวิดีโอไร้เสียง
ในปัจจุบัน โมเดล วิดีโอเป็นเสียง (Video-to-sound) ส่วนใหญ่ ซึ่งเป็นโมเดลที่ถูกฝึกให้สร้างเสียงจากวิดีโอที่ไม่มีเสียง มักทำงานได้ไม่ดีนักเมื่อเป็นเรื่องของการสร้าง เสียงพูด
ในทางกลับกัน โมเดล แปลงข้อความเป็นเสียงพูด (text-to-speech) ส่วนใหญ่ก็ไม่สามารถสร้างเสียงที่ไม่ใช่เสียงพูดได้ดีนัก เพราะถูกออกแบบมาเพื่อจุดประสงค์ที่แตกต่างกัน
นอกจากนี้ ความพยายามก่อนหน้านี้ในการรวมทั้งสองงานเข้าด้วยกัน มักตั้งอยู่บนสมมติฐานว่า การฝึกแบบร่วมกันจะทำให้ประสิทธิภาพลดลง ส่งผลให้ระบบเหล่านั้นต้องแยกการสอนเสียงพูด และเสียงประกอบออกเป็นหลายขั้นตอน ซึ่งเพิ่มความซับซ้อนให้กับการทำงานโดยรวม
จากสถานการณ์ดังกล่าว นักวิจัยจาก Apple จำนวน 3 คน ร่วมกับนักวิจัยจากมหาวิทยาลัย Renmin แห่งประเทศจีนอีก 6 คน ได้พัฒนา VSSFlow โมเดล AI ใหม่ที่สามารถสร้างได้ทั้ง เอฟเฟกต์เสียงและเสียงพูดจากวิดีโอที่ไม่มีเสียง ภายในระบบเดียว
ไม่เพียงเท่านั้น สิ่งที่พวกเขาพัฒนายังทำงานในลักษณะที่ การฝึกเสียงพูดช่วยเสริมประสิทธิภาพการฝึกเสียงประกอบ
แนวทางการแก้ไข
VSSFlow ใช้แนวคิดหลายอย่างจาก Generative AI รวมถึงการถอดเสียง (Transcript) ให้เป็นลำดับโทเคนของหน่วยเสียง (phoneme) และการเรียนรู้การสร้างเสียงกลับมาจากสัญญาณรบกวนด้วยเทคนิค Flow-matching ซึ่งเป็นวิธีที่ฝึกให้โมเดลสามารถเริ่มจากเสียงรบกวนแบบสุ่ม และค่อย ๆ สร้างสัญญาณเสียงที่ต้องการออกมาได้อย่างมีประสิทธิภาพ
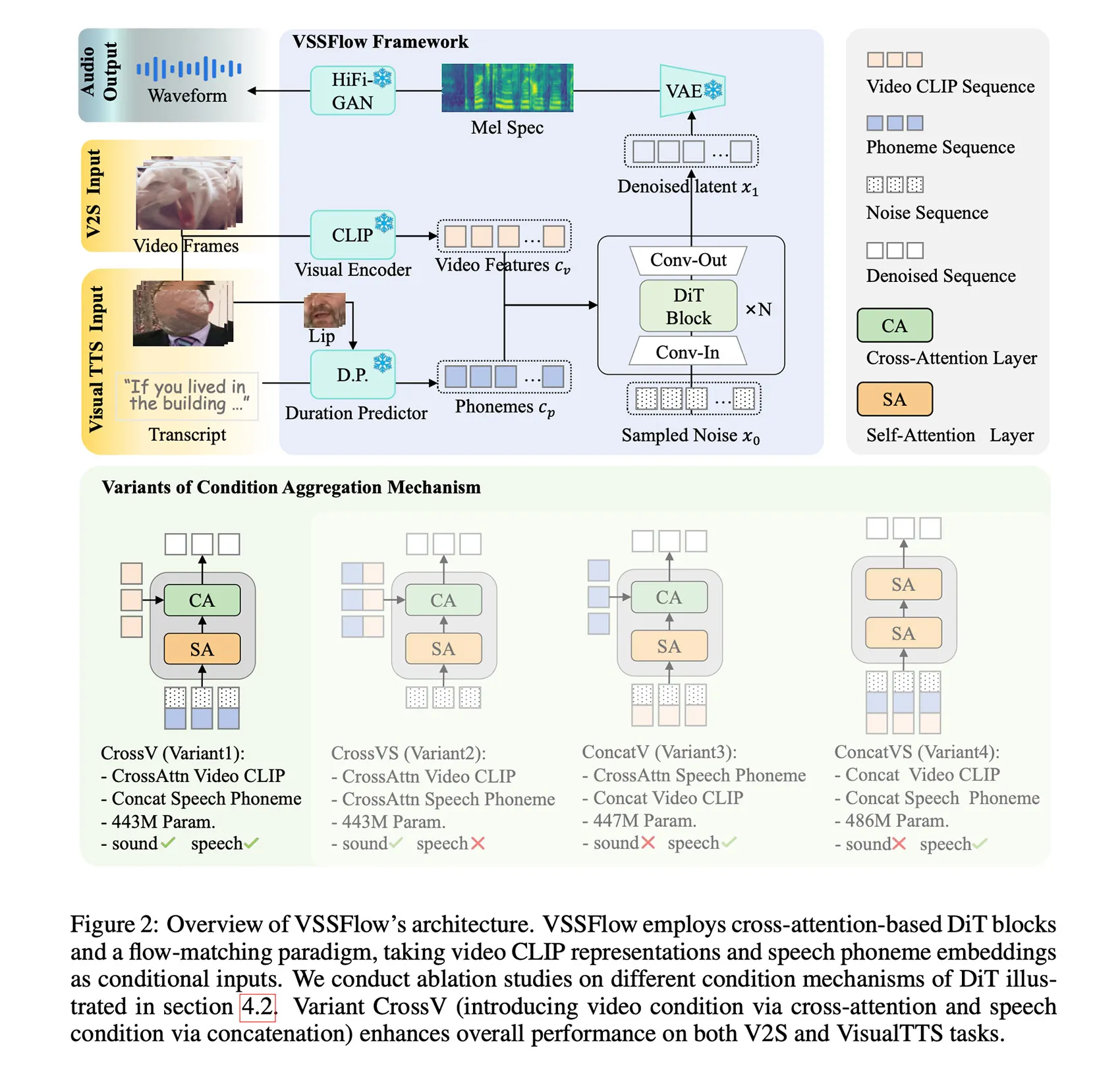
ทั้งหมดนี้ถูกบรรจุอยู่ในโครงสร้างแบบ 10 เลเยอร์ ที่รวมสัญญาณจากวิดีโอและบทถอดเสียงเข้าไปโดยตรงในกระบวนการสร้างเสียง ทำให้โมเดลสามารถจัดการได้ทั้ง เอฟเฟกต์เสียงและเสียงพูด ภายในระบบเดียวกัน
ที่น่าสนใจกว่านั้นคือ นักวิจัยพบว่า การฝึกโมเดลให้เรียนรู้ทั้งเสียงพูดและเสียงประกอบไปพร้อมกัน กลับช่วย เพิ่มประสิทธิภาพของทั้งสองงาน แทนที่จะทำให้โมเดลสับสน แข่งขันกันเอง หรือทำให้ประสิทธิภาพโดยรวมของงานใดงานหนึ่งลดลง
ในการฝึก VSSFlow นักวิจัยป้อนข้อมูลให้โมเดลในหลายรูปแบบผสมกัน ได้แก่
- วิดีโอที่ไม่มีเสียง จับคู่กับเสียงสภาพแวดล้อม (V2S)
- วิดีโอคนพูดแบบไม่มีเสียง จับคู่กับบทถอดคำพูด (VisualTTS)
- ข้อมูลแปลงข้อความเป็นเสียงพูด (TTS)
โดยปล่อยให้โมเดลเรียนรู้ทั้ง เอฟเฟกต์เสียง และ บทสนทนาเสียงพูด ไปพร้อมกัน ภายในกระบวนการฝึกแบบครบวงจร (end-to-end) เพียงระบบเดียว
อย่างไรก็ตาม สิ่งสำคัญที่นักวิจัยระบุไว้คือ ในสภาพการใช้งานเริ่มต้น VSSFlow ยังไม่สามารถสร้างเสียงพื้นหลังและเสียงพูดออกมาพร้อมกันได้อัตโนมัติในผลลัพธ์เดียว
เพื่อแก้ปัญหานี้ นักวิจัยจึงนำโมเดลที่ผ่านการฝึกมาแล้ว ไป ปรับจูนเพิ่มเติม (Fine-tune) ด้วยชุดข้อมูลสังเคราะห์ขนาดใหญ่ ซึ่งเป็นตัวอย่างที่นำ เสียงพูดและเสียงสภาพแวดล้อมมาผสมกัน เพื่อให้โมเดลเรียนรู้ว่า เสียงทั้งสองประเภทควรออกมาพร้อมกันอย่างไรในเวลาเดียวกัน
การนำ VSSFlow ไปใช้งานจริง
ในการสร้าง เสียงประกอบและเสียงพูดจากวิดีโอที่ไม่มีเสียง โมเดลจะเริ่มจาก สัญญาณเสียงรบกวนแบบสุ่ม แล้วใช้ข้อมูลภาพจากวิดีโอ ซึ่งถูกดึงมาในอัตรา 10 เฟรมต่อวินาที เพื่อกำหนดลักษณะของเสียงบรรยากาศรอบ ๆ
ในขณะเดียวกัน การถอดคำพูด (transcript) ของสิ่งที่กำลังพูด จะทำหน้าที่เป็นตัวกำหนดรายละเอียดของ เสียงพูดที่ถูกสร้างขึ้น อย่างแม่นยำ
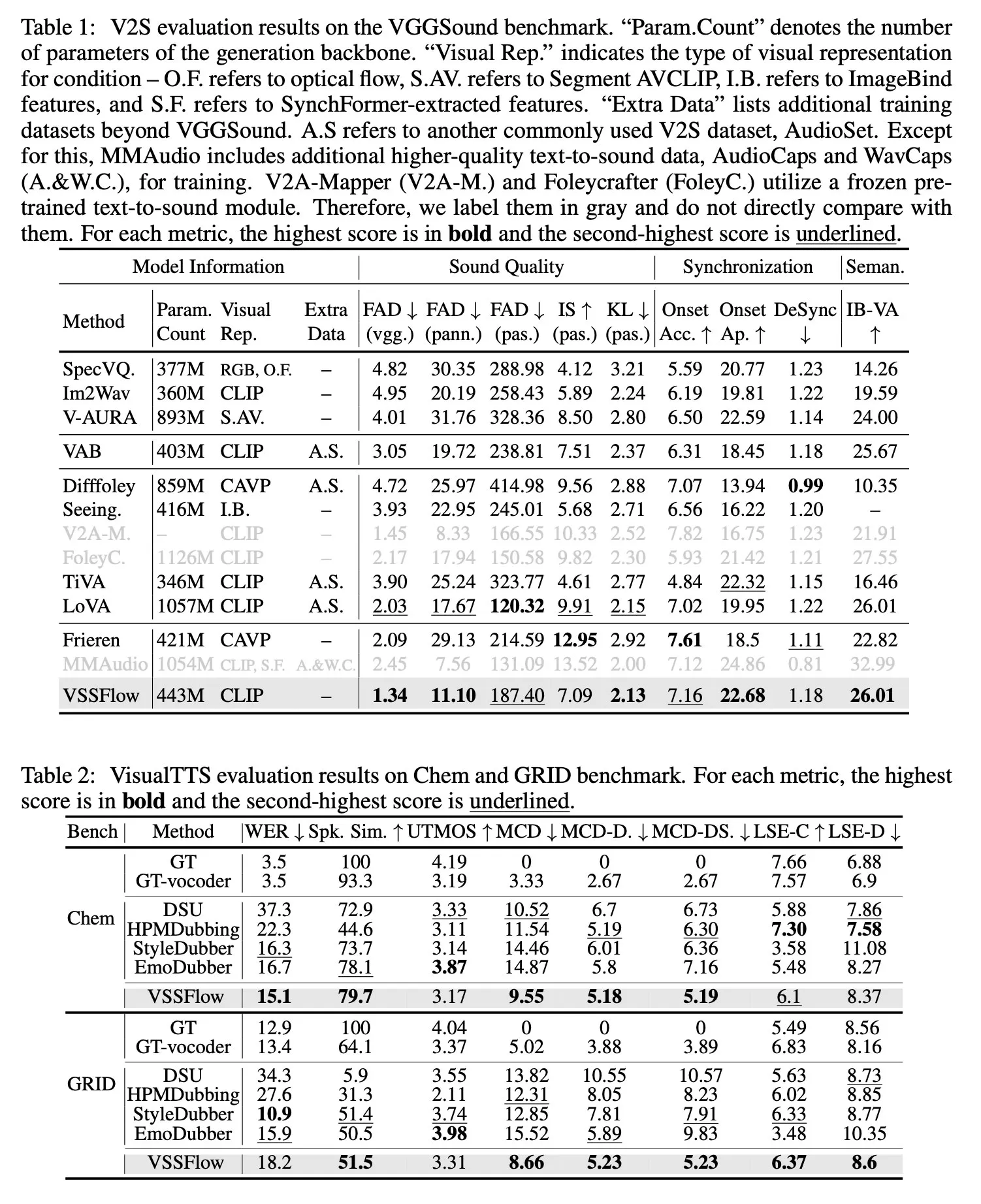
เมื่อทดสอบเปรียบเทียบกับโมเดลเฉพาะทางที่ถูกสร้างมาเพื่อ
ทำเอฟเฟกต์เสียงอย่างเดียว
หรือสร้างเสียงพูดอย่างเดียว
พบว่า VSSFlow ให้ผลลัพธ์ที่ทัดเทียม ในทั้งสองงาน และยัง ทำคะแนนนำในตัวชี้วัดสำคัญหลายด้าน ทั้งที่ใช้เพียง ระบบรวมศูนย์ระบบเดียว
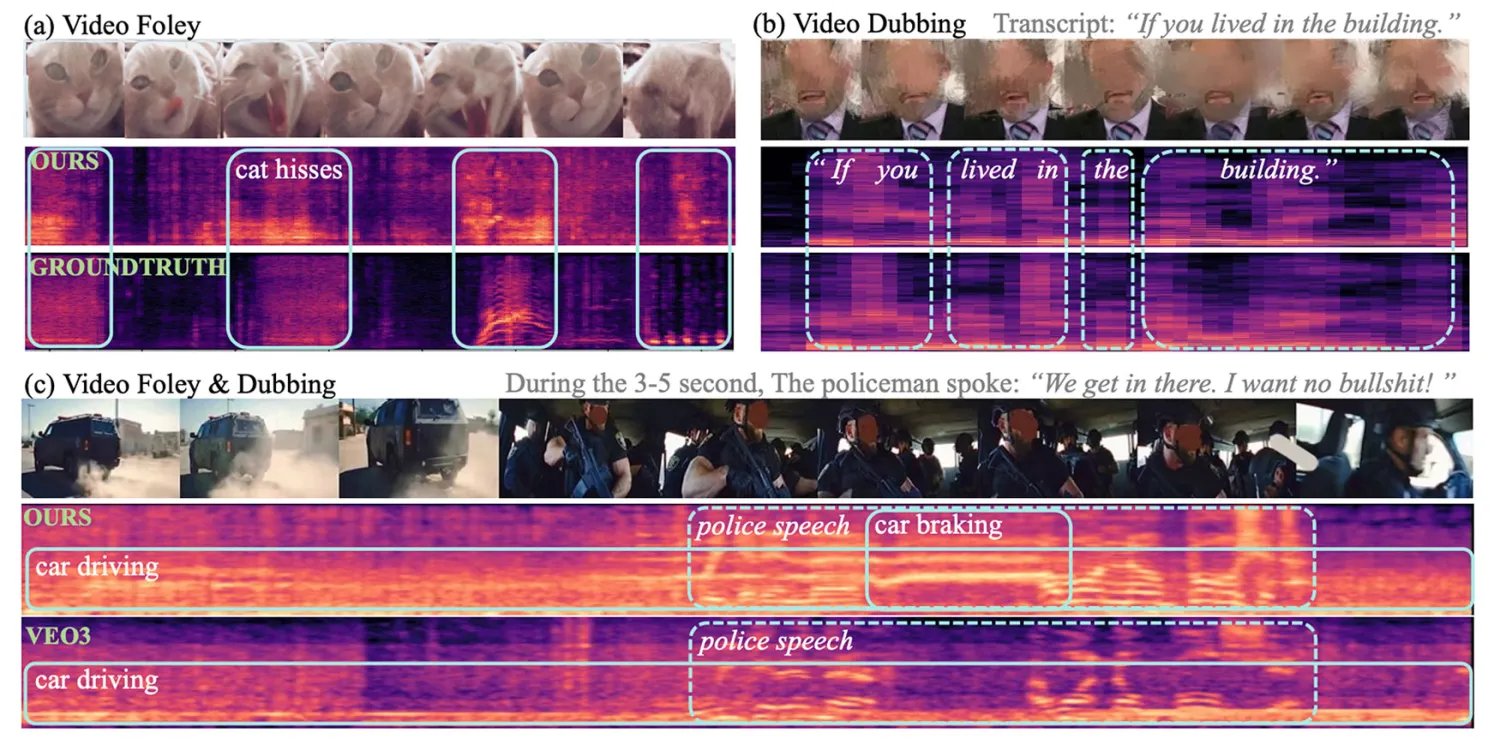
นักวิจัยได้เผยแพร่ เดโมหลายรูปแบบ ทั้งเสียงอย่างเดียว เสียงพูดอย่างเดียว และการสร้างเสียงกับเสียงพูดพร้อมกัน (จากวิดีโอ Veo3) รวมถึงการเปรียบเทียบระหว่าง VSSFlow กับโมเดลทางเลือกหลายตัว
คุณสามารถรับชมผลลัพธ์บางส่วนได้ด้านล่าง แต่แนะนำให้เข้าไปที่หน้าเดโมเพื่อดูทั้งหมด
สิ่งที่น่าสนใจ:
นักวิจัยได้เปิดซอร์สโค้ดของ VSSFlow บน GitHub แล้ว และกำลังดำเนินการเปิดเผย พารามิเตอร์ของโมเดล (model weights) เพิ่มเติมนอกจากนี้ ยังอยู่ระหว่างการพัฒนา เดโมสำหรับการทดสอบใช้งานจริง (inference demo) ด้วย
นักวิจัยระบุว่า:
งานวิจัยนี้นำเสนอโมเดลแบบ unified ที่รวมงานวิดีโอเป็นเสียง (V2S) และการแปลงข้อความเป็นเสียงพูดจากภาพ (VisualTTS) เข้าด้วยกัน สร้างแนวคิดใหม่สำหรับการสร้างเสียง และเสียงพูดที่อิงจากวิดีโอ
ได้อย่างมีประสิทธิภาพ ในการนำข้อมูลจากเสียงพูดและวิดีโอเข้าไปใช้ในโครงสร้าง DiTนอกจากนี้ เรายังแสดงให้เห็นผลลัพธ์ที่การเรียนรู้ร่วมกันระหว่างเสียงและเสียงพูดสามารถเสริมประสิทธิภาพซึ่งกันและกันได้ ซึ่งสะท้อนคุณค่าของโมเดลแบบรวมศูนย์
สำหรับงานวิจัยในอนาคต ยังมีหลายประเด็นที่ควรศึกษาเพิ่มเติม โดยประเด็นแรกคือ การขาดแคลนข้อมูลวิดีโอ–เสียงพูด–เสียงประกอบที่มีคุณภาพสูง ซึ่งเป็นข้อจำกัดสำคัญของการพัฒนาโมเดลสร้างเสียงแบบรวม
อีกหนึ่งความท้าทายสำคัญ คือ การพัฒนาวิธีแทนข้อมูลของเสียงและเสียงพูดที่ดียิ่งขึ้น ซึ่งสามารถรักษารายละเอียดของเสียงพูดไว้ได้ ขณะเดียวกันก็ยังมีขนาดข้อมูลที่กระชับ
ที่มา: 9to5Mac, Machinelearning.apple