
DeepSeek ได้เปิดตัวโมเดลใหม่ Sparse Attention ที่ออกแบบมาให้มีต้นทุนการประมวลผลต่ำลงอย่างมาก โดยเฉพาะเมื่อใช้ในการทำงาน Long Context
DeepSeek เปิดตัวโมเดล ‘sparse attention’ ที่ช่วยลดต้นทุน API ลงครึ่งหนึ่ง
เมื่อวันจันทร์ที่ 29 ก.ย. ที่ผ่านมา นักวิจัยจาก DeepSeek ได้โพสต์ประกาศเปิดตัวโมเดลทดลองใหม่บน Hugging Face พร้อมทั้งเผยแพร่บทความทางวิชาการที่เกี่ยวข้องบน GitHubโดยโมเดลใหม่ V3.2-exp ซึ่งถูกออกแบบมาให้มีต้นทุนการประมวลผล (inference) ต่ำลงอย่างมาก โดยเฉพาะเมื่อใช้ในการทำงานกับบริบทขนาดยาว (long-context)

ฟีเจอร์ที่สำคัญที่สุดของโมเดลใหม่นี้คือระบบที่เรียกว่า DeepSeek Sparse Attention ซึ่งเป็นระบบที่ซับซ้อนซึ่งหัวใจหลักของระบบนี้คือการใช้โมดูลที่เรียกว่า “lightning indexer” เพื่อจัดลำดับความสำคัญของข้อความบางส่วนที่คัดเลือกจากบริบททั้งหมด จากนั้น ระบบอีกส่วนที่เรียกว่า “fine-grained token selection system” จะทำการเลือกโทเค็น (token) อย่างละเอียดจากข้อความส่วนที่ถูกคัดเลือกมาอีกที เพื่อป้อนเข้าไปใน Attention Window ที่มีจำกัดของโมดูล เมื่อทำงานร่วมกัน ระบบนี้ช่วยให้โมเดล Sparse Attention สามารถประมวลผลข้อมูลที่ยาวมาก ๆ โดยใช้ทรัพยากรเซิร์ฟเวอร์น้อยลงอย่างเห็นได้ชัด
การทดสอบเบื้องต้นโดย DeepSeek พบว่าค่าใช้จ่ายในการเรียกใช้ API หนึ่งครั้งสามารถลดลงได้ถึงครึ่งหนึ่งในสถานการณ์ที่มีบริบทยาว ๆ อย่างไรก็ตาม ยังจำเป็นต้องมีการทดสอบเพิ่มเติมเพื่อการประเมินผลที่สมบูรณ์ยิ่งขึ้น แต่เนื่องจากโมเดลนี้เป็นแบบ Open-weight (การเปิดเผยค่าน้ำหนักของโมเดล) และเปิดให้ใช้งานได้ฟรีบน Hugging Face จึงคาดว่าอีกไม่นานจะมีการทดสอบจากหน่วยงานภายนอกเพื่อพิสูจน์คำกล่าวอ้างในงานวิจัย
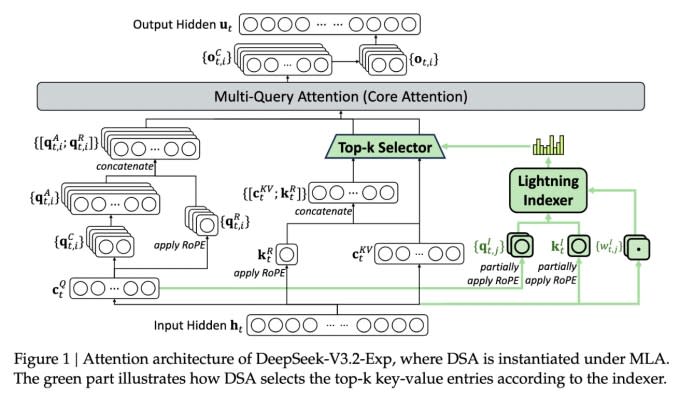
โมเดลใหม่ของ DeepSeek ถือเป็นหนึ่งในความก้าวหน้าครั้งสำคัญล่าสุดที่พยายามแก้ไขปัญหาด้านต้นทุนการประมวลผล (inference costs) ซึ่งหมายถึงต้นทุนด้านเซิร์ฟเวอร์ในการใช้งานโมเดล AI ที่ผ่านการฝึกฝนมาแล้ว (ซึ่งแตกต่างจากต้นทุนในการฝึกฝน)
ในกรณีนี้ นักวิจัยของ DeepSeek กำลังมองหาวิธีที่จะทำให้สถาปัตยกรรมพื้นฐานอย่างทรานส์ฟอร์มเมอร์ (transformer architecture) ทำงานได้อย่างมีประสิทธิภาพยิ่งขึ้น และค้นพบว่ายังมีโอกาสในการปรับปรุงที่สำคัญอีกมาก
DeepSeek ถือเป็นบริษัทที่ค่อนข้างโดดเด่นในวงการ AI โดยเฉพาะสำหรับผู้ที่มองว่าการวิจัย AI เป็นการแข่งขันเชิงชาตินิยมระหว่างสหรัฐฯ และจีน บริษัทได้สร้างความฮือฮาเมื่อต้นปีด้วยโมเดล R1 ซึ่งฝึกฝนโดยใช้เทคนิคการเรียนรู้แบบเสริมกำลัง (reinforcement learning) เป็นหลัก และมีต้นทุนต่ำกว่าคู่แข่งในสหรัฐฯ อย่างมาก อย่างไรก็ตาม โมเดลดังกล่าวยังไม่สามารถจุดประกายการปฏิวัติครั้งใหญ่ในวงการฝึกฝน AI ได้ตามที่คาดการณ์ไว้ และบริษัทก็ค่อยๆ ห่างหายไปจากความสนใจในช่วงหลายเดือนที่ผ่านมา 
แม้ว่าแนวทาง “sparse attention” ใหม่นี้ไม่น่าจะสร้างความฮือฮาได้เท่ากับโมเดล R1 แต่ก็อาจเป็นบทเรียนและเทคนิคที่สำคัญอย่างยิ่งสำหรับผู้ให้บริการในสหรัฐฯ เพื่อช่วยควบคุมต้นทุนการประมวลผลให้ต่ำอยู่เสมอ
ที่มา: finance.yahoo